Audio Redactions: The Coolest Feature I Worked On
Audio redactions is a feature that allows users to selectively mute or replace portions of audio recordings with silence or a bleep sound. This is particularly useful in legal contexts where sensitive information needs to be protected. Logikcull’s audio redactions feature was such a fun and interesting project to work on. I led the project over the course of several months and it was very satisfying to see it come together. I’m going to outline the process of designing and implementing this feature. But first, here’s a quick video to see it in action:
As you can see, there’s a lot going on - a transcript where you can click to navigate to the relevant time, a waveform showing the audio, and a list of redactions that have been applied. I’m going to break down the feature into a series of sections below:
Offset Calculations
I needed a way to communicate the positions of audio redactions between both the processing pipeline (which is responsible for actually burning in the redactions to the final audio file) and the client-side dashboard / rails app.
A user can create redactions in a variety of ways, by either selecting text they want to redact, or entering start/end time. I convert between these two formats before ultimately storing as start/end time on the server for persistence. This was a LeetCode-like problem to convert between the two formats. The key was making sure that the redactions were shown in the exact right location, which would obviously be a big issue otherwise.
Transcript Markup
There are multiple different types of markup to be shown in the transcript:
- Redactions (the black boxes covering the text)
- Persistent highlights (the pink text in screen recording)
- Search highlights (the yellow background text)
- Personally Identifiable Information (PII): These are the orange squiggly underlined text.
You can select text to redact directly, or create a redaction by a start and end time. You can also bulk create redactions matching any set of text.
The first part of this challenge was to improve the transcript view to be able to handle yet another type of markup. Previously, we had taken a relatively simple approach to markup where each highlight was wrapped with an element. For example, see the codepen below:
While simple, this approach can start to struggle when you have multiple overlapping markup, and you also want to visually convey that. For example, what if a redaction and a highlight overlap? To solve this, we ended up going with a layered approach to markup, using pseudo-elements to control positioning. See the pen below:
The data-text-before and data-text-highlight control the positioning of the markup in a more scalable way by using pseudo-elements to position the markup. You can also see how the “doubly” highlighted phrase of “emerald can” ends up having a darker gold background because of mix-blend-mode: multiply CSS rule.
Another early challenge was improving the existing transcript viewer to better handle selection of words. When you hover over a word in the transcript, the word highlights, and you can click the word to navigate to that section of the audio file:
Previously, that worked by having every single word (and even spaces in between!) as a separate DOM node. This became problematic for larger, hour-long audio files which could easily have 15,000 DOM nodes! I changed it so that each chunk of text is a single DOM node, and we dynamically insert a highlight DOM node depending on where the user’s cursor is. This reduced the number of DOM nodes by 100x, significantly improving memory usage and render performance. It also meant we didn’t even have to virtualize the transcript text (which is nice to keep the browser find functionality). The effect on the number of DOM nodes can be easily seen with this comparison:
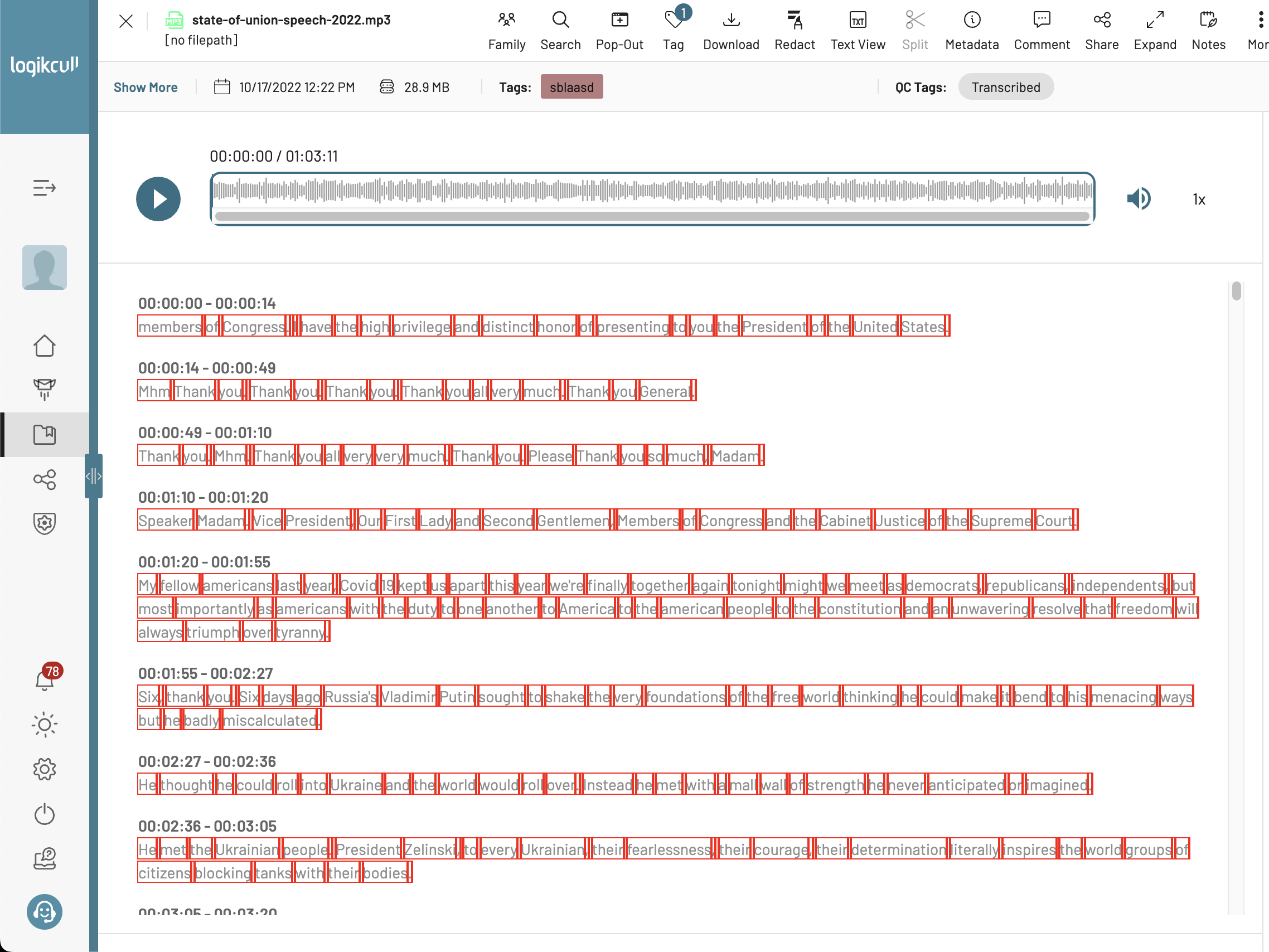 Before: each red box shows a separate DOM node
Before: each red box shows a separate DOM node
And after:
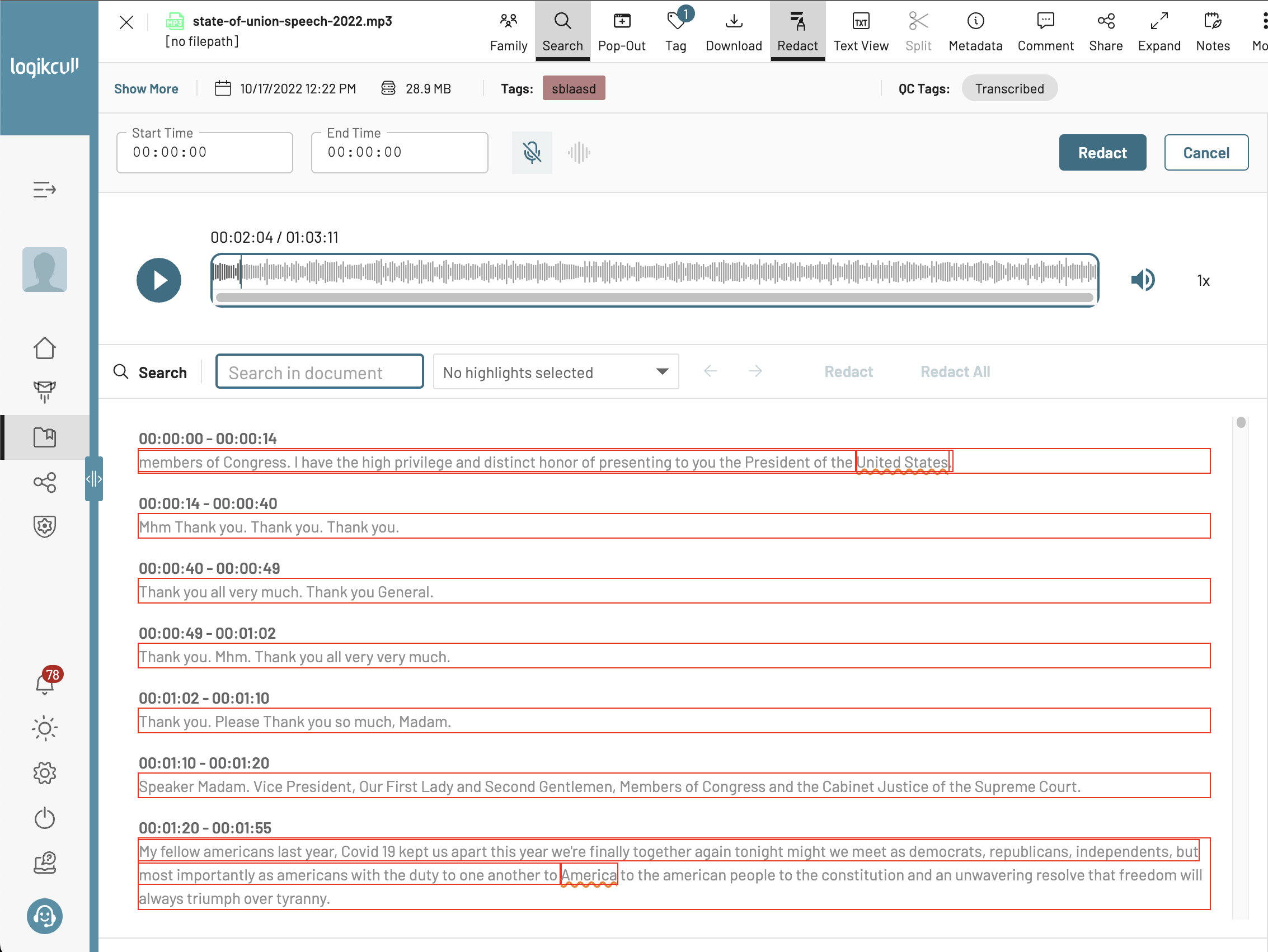 Fewer DOM nodes with no loss in functionality 🥳
Fewer DOM nodes with no loss in functionality 🥳
The logic for enabling click-to-navigate functionality for each word binary searches to identify the target word based on the cursor’s x and y coordinates during mouse movement. The sandbox below demonstrates a simplified version of this in action:
Audio Interactions
We needed to preview the audio with any applied redactions for the user to hear back and verify. We don’t actually modify the native audio file in the browser, so we needed to “fake” this client-side.
This involved working with the Audio Context API to manipulate the audio file in real-time as the user was playing it back and making edits to redactions. We also needed to account for whether the user wanted a bleep noise or silence for redactions.
We also show a waveform preview of the audio file which the user can click on to navigate around to different timestamps.
Redacting Across Multiple Audio Files
I worked on applying the same offset calculation logic to allow users to redact terms across any number of audio files (bulk redactions). I won’t go too much into the specifics, but it involved using the same client-side code and putting it into a lambda that would run across each file.
Overall this feature was a ton of fun to see through and I was proud of the successful result. The project combined several interesting technical challenges - from DOM optimization and real-time audio processing to complex text-to-time calculations. It perfectly encapsulated why I enjoy building on the web: the ability to create powerful, user-friendly tools that solve real problems.